
Deep-Fakes
Published:
What are DeepFakes ?
Deepfakes are synthetic media in which a person in an existing image or video is replaced with someone else’s likeness. While the act of faking content is not new, deepfakes leverage powerful techniques from machine learning and artificial intelligence to manipulate or generate visual and audio content with a high potential to deceive. The main machine learning methods used to create deepfakes are based on deep learning and involve training generative neural network architectures, such as autoencoders or generative adversarial networks (GANs).
DeepFakes are realistic-looking fake videos, in which it seems that someone is doing and/or saying something even though they didn’t.
How Deepfakes are Created?
The basis of deepfakes, or image animation in general, is to combine the appearance extracted from a source image with motion patterns derived from a driving video. For these purposes deepfakes use deep learning, where their name comes from (deep learning + fake). To be more precise, they are created using the combination of autoencoders and GANs.
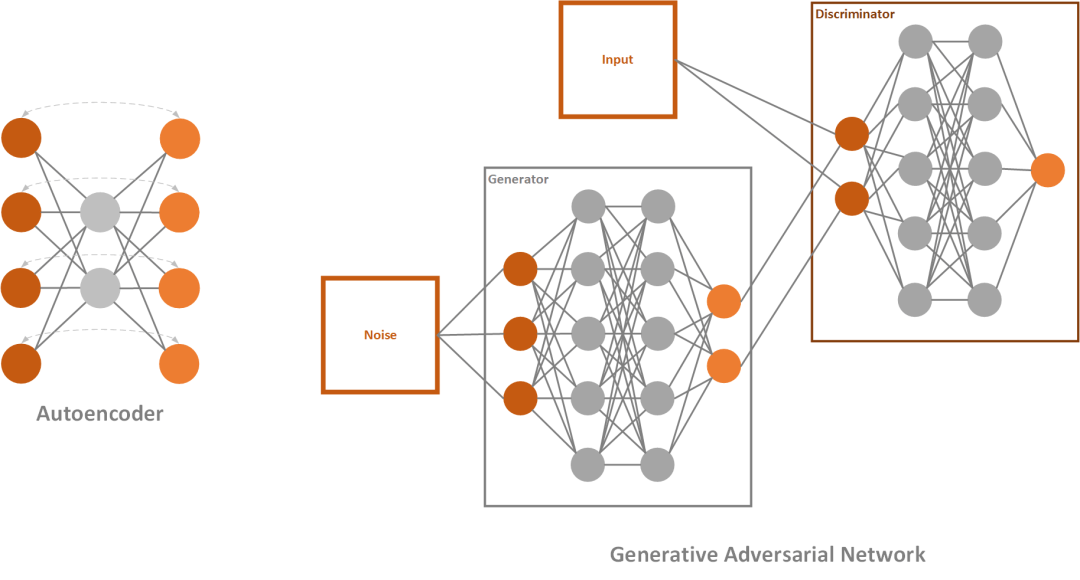
Autoencoder is a simple neural network, that utilizes unsupervised learning (or self-supervised if we want to be more accurate). They are called like that because they automatically encode information and usually are used for dimensionality reduction.
Generative Adversarial Networks or GANs are composed of two networks that are competing against each other. The first network tries to generate images that are similar to the training set and it is called the generator. The second network tries to detect where does the image comes from, training set, or the generator and it is called – the discriminator.
Learn more about Autoencoders and GANs here.
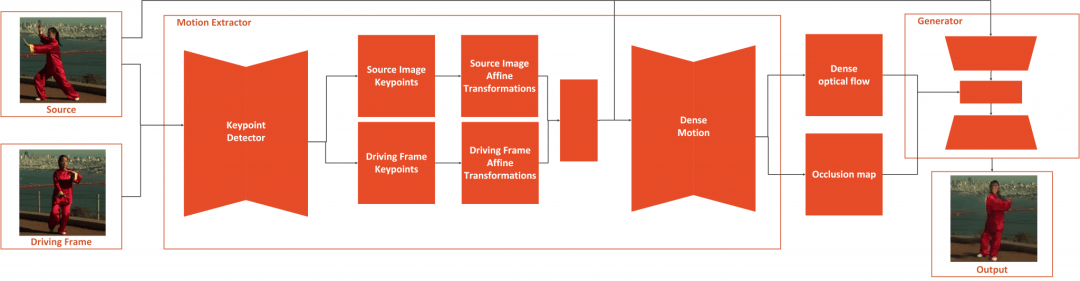
First Order Model for Image Animation
The whole process of First Order Model is separated into two parts: Motion Extraction and Generation. As an input the source image and driving video are used. Motion extractor utilizes autoencoder to detect keypoints and extracts first-order motion representation that consists of sparse keypoints and local affine transformations. These, along with the driving video are used to generate dense optical flow and occlusion map with the dense motion network. Then, the outputs of dense motion network and the source image are used by the generator .
It also has features that other models just don’t have. The really cool thing is that it works on different categories of images, meaning you can apply it to face, body, cartoon, etc. This opens up a lot of possibilities. Another revolutionary thing with this approach is that now you can create good quality Deepfakes with a single image of the target object, just like we use YOLO for object detection.

Building your own Deepfake
Please refer my Colab Notebook for the same.
Result
